Table of Contents
List of Figures
Table of Contents
ResFool is a Mac OS X-native resource editor. It supports editing traditional Mac resource forks as well as newer, data fork based resource forks. It can also edit (though not create) Bundle folders (such as .app and .rtfd folders). This chapter introduces the basic interface of ResFool.
New resource files are created using either the or the item from the File menu. Standard resources are stored separately from the data in the file, in what is known as the Resource Fork (as opposed to the Data Fork). However, other operating systems typically cannot represent a file with both these "forks", so only the data fork is preserved. Mac OS X introduced the concept of a Resource Fork contained entirely in the Data Fork of a file. Internally, all the same data typically stored in the resource fork of a file is instead stored in the data fork of the file. These files can safely be moved between file systems, as the actual file has only a single fork. Since the data fork is being used for the resource data, these files have no "data" other than the resources stored in it.
Any type of file may be opened in ResFool. If the file is a standard, dual-fork Mac file or a file with only a resource fork, the resource fork is opened and displayed. If the file has resource data stored in the data fork, the data fork is opened as a resource file. If the file has only a data fork with no resource information stored in it, you will be prompted to create a new, empty resource fork for the file.
In addition to simple files, Mac OS X stores documents as a collection of files in a special type of folder known as a "bundle". In fact, ResFool itself is distributed in precisely that form. Bundles introduce a third conceptual form of resource data - individual files that store resource data without a container to store the resource meta data. Such resource files are typically stored in a "Resources" folder in the bundle (though, the specific location may vary with Bundle type). This folder may also contain data fork based resource files. In addition, there may be a collection of subfolders that are used for localizing a bundle to a particular language. ResFool can open bundles just like any other file. All the individual resource files will be displayed, including any resources stored in data fork based resource files. The localized resources stored in the folder for the current locale will also be displayed. These resources may be edited and deleted like any other resource file type. New resources may be created, though they will all be stored in the main resources folder as individual files.
The , and items are generally self-explanatory. However, it is important to note that the type of a file cannot be changed using . So, if a file was created as a standard resource fork-based file, it cannot be saved as a data fork-based resource file. To accomplish that, one may make judicious use of select all and copy-and-paste.
The main resource list is the window first opened when viewing a new or existing document. This hierarchical list displays every resource type currently stored in the document, the number of those resources and their total size. When a list row is toggled open the resources of that particular type are displayed, with their ID (if applicable), name and size. See figure 1.1 for an example.
![[Note]](images/note.png) | Note |
|---|---|
| Sizes in the various resource lists are specified in bytes unless otherwise indicated. A value ending in 'K' is 1024 bytes and 'M' is 1024 'K'. | |
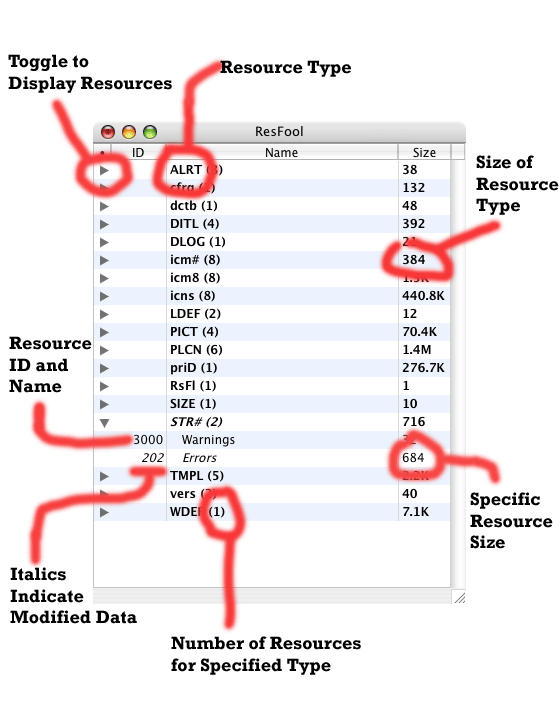
The main resource list can be used to add, modify or remove individual resources. You can also add new types, delete all resources of a specific type or change the attributes (name, ID, type, etc.) of resources.
Adding a resource to a document can be done by choosing "New Resource..." from the "Resource" menu. You will be able to specify a type, ID and name for the new resource. For your convenience, a list of known types (those types for which a template is available) is provided. Depending on the type of file being edited, either the ID or name must be unique for the specified type. Traditional and data-fork based resource files must have unique IDs. Bundle based resources must have unique names.
Resources can also be copied between resource files. When copying from one file to another from ResFool, all resource attributes will be preserved. Arbitrary data on the clipboard can also be pasted into the main document list. This will result in all data types available on the clipboard being added to the document, using the clipboard type as the resource type. For instance, copying styled text from TextEdit and pasting it into a new resource document will create resource types 'RTF ', 'styl', 'TEXT', 'ustl' and 'utxt'. These new resources will be created with the same IDs. So, when pasting this to a document that already has a 'TEXT' resource with ID 128, all the new resources will be assigned an ID of 129.
Resources may be delete by selecting one or more individual resources and pressing the delete key. You may also delete an entire resource type by selecting it and pressing the delete key. If a resource type is toggled open and some of its resources are selected, you will not be able to extend the selection to include the type itself. Instead, either first deselect the individual resources or simply select the type without attempting to extend the selection.
In the main resource list, you may directly edit the ID or name of an individual resource by clicking once in the appropriate area of the list. After a brief pause, the field for the resource you have selected will become an editable text field. Type either a new name or ID and press return to commit the change. Various flags may also be set for particular resources using the menu. For example, selecting will modify the locked attribute of the resource. There is no visual feedback of this in the main resource list, although the menu item will be displayed with a check mark beside it.
If you would prefer to modify the ID and name of a batch of resources, or change their type, you can select all the resources of interest (or an entire resource type) and choose from the menu. The resulting dialog will allow you to change the name, ID and type of all the selected resources.
Individual resource types may be viewed in their own window if the hierarchical view of the main window proves to be too cumbersome. In addition to the ID, Name and Size displayed in the main document window, the type window displays the resource flags for each resource and, when available, a graphic preview of the resource (see figure 1.2 for an example of the 'PICT' type).

| Note |
|---|---|
| The preview used to display data of a particular type may be set in the user preferences. List previews may also be globally toggled on or off in the preferences. | |
Individual resources may be manipulate in the same ways as are possible in the main resource list. The ID or name may be modified by clicking in the appropriate field or by using the menu item. When creating a new resource you will not be presented with a dialog, as only resources of the current type can be created. The ID will be assigned based on the default starting ID for the resource type. If already in use, the ID will be incremented until an unused value is found. If this is a bundle, a unique name will be generated instead.
ResFool treats bundles as if they were files with resource forks from a UI standpoint. However, there are some significant differences in their actual implementation. Although ResFool attempts to hide these differences, you may need to understand some of these issues.
In traditional resource files information about the resources, such as name, ID and flags are stored in a special meta data section of the binary file. In a bundle based resource file which uses individual files to store each resource, there is no special meta data section. Mac OS X simply uses the file system to store meta data, which limits it to the resource name and type. So, given a resource file named "application.icns", the name of the resource is "application" and its type is "icns". Note that no ID is available, and the type of the resource may be any length. This is at odds with traditional resource forks which use the ID to uniquely identify the resource and requires the type to be exactly four characters. To confuse matters even more, bundle resource forks may also include traditional resource fork files which are conceptually merged with the individual resource files, but are constrained by the normal resource fork limitations.
To handle this, ResFool will display an individual file resource with "N/A" for the ID. It will also enforce unique names for these resources. When adding a new resource type, you will be allowed to enter more than the traditional four characters. New resources are always added as individual resource files in the non-localized resource folder. At the current time, there is no way to add a resource for a specific localization or view resources not in the current system language, nor can resources be added to any traditional resource files found in the resource folder of the bundle. To add resources to specific, traditional resource files, you will need to manually open those files after displaying the contents of the bundle.
Table of Contents
The ability to edit arbitrary resource data is ResFool's most powerful feature. Using a combination of hex editing and templates, it is possible to edit a plethora of binary formats. Using the template mechanism, it is possible to describe arbitrary binary formats and display them using standard graphical interface elements. ResFool ships with over 100 such templates, but new ones can be created and added to ResFool with a minimum of effort.
We begin our foray into the generic resource editor by looking at its overall interface. An example editor window is shown if Figure 2.1. This window is currently displaying a template for a custom type called 'Palt', a color palette.
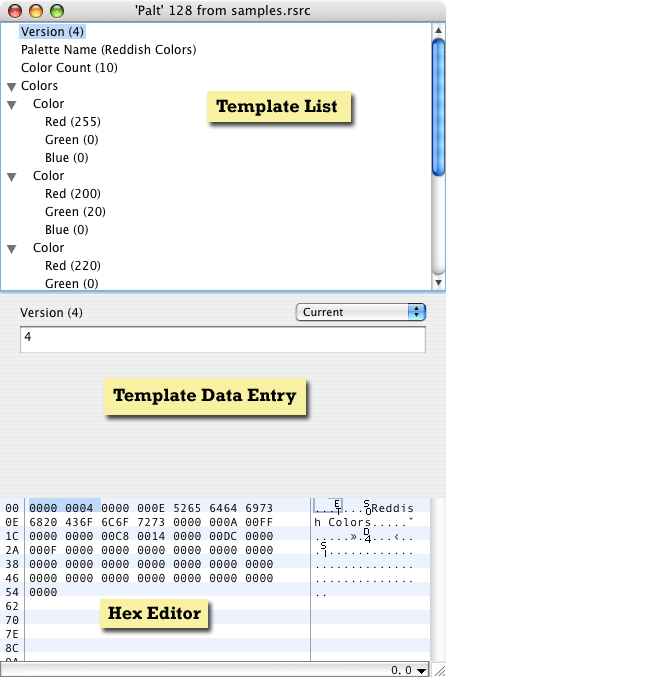
Note the general areas for the editor window. The Template List shows the binary resource data parsed by the template supplied for the 'Palt' type. The list shows the name of the element with its current value in parenthesis. Templates may have lists of items, as seen in this example. In this case, it is a list of 10 Color elements. The color elements themselves consist of structured data, a numeric value for the Red, Green and Blue components.
Selecting an element from the template list will hilite the binary data in the hex view (if it is visible) associated with the selected field and will alter the template data entry area to reflect the controls appropriate for editing the type of data selected. In figure 2.1 a numeric entry field is visible. Also available in this instance is a popup just above the entry field that reads "Current". This menu is populated from any 'case' statements specified in the template for this resource type (see the section on templates, below, for more details).
If no template was found for the specified resource type, the editor window will open with the hex editor occupying the entire window contents. If you would like to view this data with a template not assigned for it in the resource type mappings, choose from the menu. You can then choose the template type to (temporarily) use for this resource.
ResFool supports nearly 100 template types for crafting a wide range of individual templates for interpreting arbitrary binary data. ResFool ships with around 100 pre-made templates, but the true power of templates is using them to describe new binary formats. This section contains descriptions of all the template types ResFool supports, including examples of their use.
Numeric types are used when a data structure contains some form of number. It may be an integer (signed or unsigned) or floating point value. Many of the these types represent integer data of one, two or four bytes and differ only in how the data is entered in the resource editor UI.
| DLNG, DWRD, DBYT | Decimal Long/Word/Byte The decimal long, word and byte type specify a signed integer value occupying four, two or one bytes, respectively. These types do not account for alignment (see Alignment types, below). Given this C struct:
struct {
short int left;
short int top;
short int right;
short int bottom;
} Rect;
a reasonable template would be: RECT { Values for the long type range from -2147483648 to 2147483647. Values for the word type from -32768 to 32767. Values for the byte type range from -128 to 127. | ||||||||
| ULNG, UWRD, UBYT | Unsigned Long/Word/Byte The unsigned long, word and byte type specify an unsigned integer value occupying four, two or one bytes, respectively. These types do not account for alignment (see Alignment types, below). Given this C struct:
struct {
unsigned long int time;
unsigned short int id;
} track;
a reasonable template would be: TRCK { Values for the long type range from 0 to 4294967295. Values for the word type from 0 to 65535. Values for the byte type range from 0 to 255. | ||||||||
| HLNG, HWRD, HBYT | Hex Long/Word/Byte The hex long, word and byte type specify an integer value in hex occupying four, two or one bytes, respectively. These types do not account for alignment (see Alignment types, below). This field is useful when specific hex values should be entered. Values for the long type range from 0 to 0xFFFFFFFF. Values for the word type from 0 to 0xFFFF. Values for the byte type range from 0 to 0xFF. | ||||||||
| FLNG, FWRD, FBYT | Filler Long/Word/Byte The filler types specify four, two and one byte values that are used to fill a structure. These are invisible values that will not be shown in the template list, though they will appear in the hex data. Items marked as "unused" in structures are good candidates for these types. When combined with an appropriate "case" statement, they will default to the correct value.
struct {
unsigned long int version;
unsigned long int unused; //should be 0xDEADBEEF
unsigned long int flags;
} data;
could be represented as: data {
The value of these items cannot be set from the template editor. | ||||||||
| REAL, DOUB | Real/DoubleThese fields represent four and eight byte floating point values. Data may be entered as simple numbers with a decimal, or using scientific notation (e.g. either .00000001 or 1.0e-9). |
String data represents a block of text data. Strings can be represented in a variety of ways, from Pascal strings to C strings, padded or not, word or long counted, etc. There is a string type to fit just about any representation.
| PSTR, ESTR, OSTR | Pascal String/Even Pad/Odd Pad Pascal strings consist of a byte count followed by up to 255 single-byte characters. The minimum number of bytes used by this type is one with a value of zero. This field has a maximum size of 256 bytes (255 characters). Since the length of the string is variable and may cause alignment problems, the ESTR and OSTR types are provided to handle alignment issues without requiring a separate alignment value. Using an Even Pad pascal string, the field immediately following the string will be placed on an even boundary. An Odd Pad string will force the following field on an odd boundary. This is accomplished by inserting a single byte with a value of zero when necessary. | ||||||
| CSTR, ECST, OCST | C String/Even Pad/Odd Pad C strings consist of a series of single-byte characters followed by a single-byte zero. The minimum number of bytes used by this type is one with a value of zero. There is no maximum size imposed by this type. Since the length of the string is variable and may cause alignment problems, the ECST and OCST types are provided to handle alignment issues without requiring a separate alignment value. Using an Even Pad C string, the field immediately following the string will be placed on an even boundary. An Odd Pad string will force the following field on an odd boundary. This is accomplished by inserting a single byte with a value of zero when necessary. | ||||||
| BSTR, WSTR, LSTR | Byte/Word/Long Count String Counted strings consist of one, two or four bytes identifying the length of the string followed by the string data. The minimum number of bytes used by this type is a length field with a value of zero (one, two or four). This field has a maximum size of 256/65537/4294967299 bytes, including the length field. The BSTR type is functionally equivalent to the PSTR type. It is included here for symmetry. | ||||||
| Pnmm, Cnmm, Tnmm | Pascal/C/Text Fixed Width Fixed width text fields always use the amount of space specified in their type, from 0 to 2559 bytes (see note "Variable Size Template Items"). A string does not need to use all bytes assigned in this field - any excess bytes will be set to 0. So, the string "Hello" stored as a P020 will have a byte with the value '5', followed by the 5 bytes of 'Hello' followed by 26 bytes of zero. For example, this structure:
struct {
unsigned long int version;
unsigned char name[32];
char address[512];
} IDCard;
could be represented as: IDCD {
| ||||||
| CHAR | Single-byte Character A character that occupies exactly a single byte. Equivalent to T001. | ||||||
| TXTS, TEXT | Text Dump A text dump indicates uncounted, unterminated text to the end of the enclosing structure. Typically, this means all data until the end of the resource should be considered text. In such cases, 'TXTS' must appear as the last item in the template and may be the only item. These fields may also appear in more complex structures (e.g. keyed lists). They must appear at the end of a structure, and it must be possible to calculate the size of the structure, or it must appear as the last element of the template. A common use would be a structure like this, where the structure will be created with enough storage for variable length text:
struct {
unsigned long int version;
unsigned char name[32];
char address[1];
} IDCard;
This might be represented as: IDCD {
| ||||||
| BHEX, WHEX, LHEX | Byte/Word/Long Hex Dump Hex dumps consist of one, two or four bytes identifying the length of the data followed by the hex data. The minimum number of bytes used by this type is a length field with a value of zero (one, two or four). This field has a maximum size of 256/65537/4294967299 bytes, including the length field. The data must be edited in hex. These types are useful to represent unknown data whose length is available. | ||||||
| BSHX, WSHX, LSHX | Byte/Word/Long Hex (Count Included) Dump Hex dumps consist of one, two or four bytes identifying the length of the data followed by the hex data. The minimum number of bytes used by this type is a length field with a value of one, two or four (one, two or four bytes long). This field has a maximum size of 255/65535/4294967295 bytes, including the length field. The data must be edited in hex. These types are useful to represent unknown data whose length is available and includes the length field itself. | ||||||
| Hnmm, Fnmm | Fixed-width Hex Dump/Filler Specifies a fixed-width field that contains unknown data. The hex dump may be edited as hex when viewing a template, the filler is not editable or visible when viewing the template. | ||||||
| TNAM | Type Name A four byte field used to identify a Mac type, typically an applications creator code or file type. | ||||||
| DATE, MDAT | Date/Modification Date A four byte date field. It is the number of seconds that have passed since January 1, 1904, the traditional Mac epoch. The Modification Date field automatically updates to the current date and time when the resource is opened. |
Lists represent a set of template fields that are repeated some number of times. At the very minimum a list must have a start and end identified, though it may also have other information used to determine the length of an actual list instance. Any template fields encountered between the start and end are used to define a single entry in the list. ResFool will duplicate the entry as many times as necessary to process all the data associated with a list in the resource.
| LSTB | Begin Indefinite List This item introduces an indefinite list of items. All data found in a resource after this item is interpreted as elements of the list. Since there is no count or end condition for this type of list, the list must be the final element of a template. For instance, if you wanted to represent a resource that consisted of a list of a two byte key and a Pascal string, you might define this template:
PLST {
| ||||||||||||||
| LSTC | Begin Counted List This item introduces a list of items with an associated count field. This item simply indicates the start of the list, it does not represent the count. The closest list count type at the same nesting level as the list above this item is used as the count (see the various list count types in this section). Since the number of elements in a counted list can be determined, these lists may appear anywhere in a resource template, at any nesting level (even inside other lists) as many times as needed. This template could be used to define a list of Pascal strings preceded by a two byte count:
STR# {
| ||||||||||||||
| LSTZ | Begin Zero-Terminated List This item introduces a list of items which is terminated by a single byte with a value of 0x00. This item simply indicates the start of the list. The list will have as many items as can fit until the first zero byte is encountered. Since the number of elements in a zero-terminated list can be determined, these lists may appear anywhere in a resource template, at any nesting level (even inside other lists) as many times as needed. In general, use of this type should be avoided. | ||||||||||||||
| LSTS | Begin Sized List This item introduces a list of items whose entire size in bytes is known. This item simply indicates the start of the list, it does not represent the size of the list. This list type must be surrounded by a SKIP (or related field) and SKPE pair. The SKIP field will automatically update a byte count indicating the total size of the list. Since the number of elements in a sized list can be determined, these lists may appear anywhere in a resource template, at any nesting level (even inside other lists) as many times as needed, though they must obey the nesting requirements of SKIP/SKPE pairs. This list type is useful when you wish to be able to quickly jump over a list of variable length data, without examining the contents of every list entry. For example, imagine a list of where each entry is a name and phone number pair (two Pascal strings). After the list data is a single byte which gives a dialing prefix used for all phone calls. This could be represented with a counted list, but getting the dialing prefix (in your code) requires examination of both strings in every list entry. Instead, you could place a single, four byte field at the beginning of the resource which contains the size, in bytes, of the list data. To get the dialing prefix would then be accomplished by jumping to the offset specified in that field. This would be specified like this (ResFool will calculate the size field for you):
PhNm {
For more information on SKIP/SKPE pairs, see the section on Skip Offsets and Sizeof values. | ||||||||||||||
| LSTE | End List Marks the end of a list structure started with LSTB, LSTC, LSTZ or LSTS. Represents no data in the resource. This item simply identifies the end of a group of template items which will be used to define a single entry in a list. | ||||||||||||||
| BCNT, OCNT, LCNT | Byte/Word/Long List Count These types represent one, two or four byte list count values. They must appear at the same level and somewhere before a counted list (LSTC) entry. Their value is automatically set by ResFool when entries are added to or removed from the associated counted list. Their value is the number of items stored in the list. | ||||||||||||||
| ZCNT, LZCT | Zero-based List Count/Long Zero-based List Count These types are two- or four-byte signed integers. They must appear at the same level and somewhere before a counted list (LSTC) entry. Their value is automatically set by ResFool when entries are added to or removed from the associated counted list. Their value is the number of items stored in the list minus 1. So, a ZCNT with a value of 0 indicates a list with 1 entry while a value of -1 indicates an empty list. | ||||||||||||||
| FCNT | Fixed-width List Count Unlike other list count fields, the fixed-width count does not represent any data in the resource. Instead, it uses the first numeric value found in the template name to determine the number of list elements. It must appear at the same level and somewhere before a counted list (LSTC) entry. The list will always have exactly the number of elements listed in the label for the field. |
Bits and bit fields are used to represent boolean data. Typically this data is a set of flags stored in one, two or four bytes, with each bit identifying a boolean state.
| BBIT, WBIT, LBIT, BBmm, WBmm, LBmm | Bit in a Byte/Word/Long/Bits in a Byte/Word/Long These fields represent a bit (or bits) in a one, two or four byte set of flags. The 'xxIT' versions identify a single bit. The 'xxmm' versions must specify the number of bits (in decimal) used by the field. The 'mm' should be replaced with a value of 02-08, 02-16 or 02-32, depending on the field width (byte/word/long). When one of these fields is encountered there must be an adequate number of following, same type fields to make a complete flag set. For instance, a BBIT must be followed by seven more BBIT fields or a BB07 field. Bit order starts with the most significant bit first. To create a template with a single byte of flag data, where only the least-significant 4 bits are used:
Bits {
| ||||||||||
| BFLG, WFLG, LFLG | Byte/Word/Long Flag These fields specify a single boolean value occupying one, two or four bytes. Their value can be either zero (false) or one (true). | ||||||||||
| BOOL | Boolean This field is a two byte boolean flag. If either byte contains a non-zero value, it is considered true. ResFool uses the hex value 0x0100 to represent true when the flags checkbox is toggled to the on setting. |
Keyed lists specify a set of possible descriptions, only one of which will be used to interpret the data found in the resource. For example, if your resource was an inventory of clothing, you might have entries that identify shirts, pants and dresses, all stored as the same resource type with some common information (price, quantity on hand, etc). However, certain values would be specific to the article of clothing (e.g. pants would have a length and waist measure, while dresses would have a single size). A keyed list lets you pick the type of data to store.
A keyed list is introduced by one of the key type fields (e.g. KWRD). This is followed by a series of CASE fields, which are in turn followed by a series of KEYB...KEYE pairs. The number of CASE statements must match the number of KEYB...KEYE pairs, except in a special case where there can be one extra KEYB...KEYE pair. When a case is chosen from the value popup while editing a resource, the matching key data is used to create the new keyed data. Given our clothing example, we could write the following template:
CLOT {}
Name PSTR
Quantity UWRD
Price UWRD
Item KWRD
Pants=0 CASE
Dress=1 CASE
Shirt=2 CASE
Pants KEYB
Waist UWRD
Length UWRD
end KEYE
Dress KEYB
Size UWRD
end KEYE
Shirt KEYB
Neck UWRD
end KEYE
| KEYB, KEYE | Keyed List Item Begin/End These fields surround a single entry in a keyed list. They do not represent actual data in the resource. They identify which set of template fields should be used to process the resource data. There must be as many pairs of these fields as there are CASE statements for the key type of this list (or one more, in certain circumstances). |
| KBYT, KWRD, KLNG | Byte/Word/Long Key Type One, two and four byte signed fields that introduce a keyed list. When parsing the resource data, this value is read and a CASE statement with a matching value is found. The index of that case statement is then used to find the correct KEYB field that starts the enclosed data, which is then used to represent the stored information. |
| KUBT, KUWD, KULG | Unsigned Byte/Word/Long Key Type One, two and four byte unsigned fields that introduce a keyed list. When parsing the resource data, this value is read and a CASE statement with a matching value is found. The index of that case statement is then used to find the correct KEYB field that starts the enclosed data, which is then used to represent the stored information. |
| KHBT, KHWD, KHLG | Hex Byte/Word/Long Key Type One, two and four byte fields that introduce a keyed list. The values in the CASE statements should be specified in hexadecimal. When parsing the resource data, this value is read and a CASE statement with a matching value is found. The index of that case statement is then used to find the correct KEYB field that starts the enclosed data, which is then used to represent the stored information. |
| KTYP | Type Name Key Type Four byte field that introduces a keyed list. The values in the CASE statements should be specified as four characters (a mac type). When parsing the resource data, this value is read and a CASE statement with a matching value is found. The index of that case statement is then used to find the correct KEYB field that starts the enclosed data, which is then used to represent the stored information. |
| KRID | Resource ID Key Type This field does not represent any data. Instead, it uses the ID of the resource as the value for the keyed list. So, a resource whose ID is 128 would match a CASE statement whose value was set to 128. When parsing the resource data, this value is read and a CASE statement with a matching value is found. The index of that case statement is then used to find the correct KEYB field that starts the enclosed data, which is then used to represent the stored information. |
Skip types consist of a size field followed by a skip end, with an arbitrary number (and kind) of intervening fields. The value in the size field is automatically updated as the data stored in the intervening fields changes. This allows you to easily create data that can be quickly skipped to find other important data.
| BSIZ, WSIZ, LSIZ | Byte/Word/Long Sizeof One, two and four byte fields that introduce a skip offset section. The value stored here is the size of the data found between this field and the next SKPE at the same nesting level. It does not include its own size. These values are calculated automatically by ResFool and cannot be edited directly. |
| BSKP, WSKP, LSKP | Byte/Word/Long Skip One, two and four byte fields that introduce a skip offset section. The value stored here is the size of the data from this field to the next SKPE at the same nesting level. It includes its own size. These values are calculated automatically by ResFool and cannot be edited directly. |
| SKIP | Skip Two byte field that introduces a skip offset section. The value stored here is the size of the data from this field to the next SKPE at the same nesting level. It includes its own size. These values are calculated automatically by ResFool and cannot be edited directly. Identical to a WSKP field. |
| SKPE | End Skip This field does not represent any actual data in the resource. It marks the last field in the template that is to be included in the size of a skip start entry. |
Binary data stored in resources is often written directly from in-memory structures. Due to platform architecture details or simply performance reasons, not all data is packed into the smallest number of bytes. Data may be aligned on two or four byte boundaries, or some other arbitrary number of bytes. It is difficult to force alignment by adding pad bytes when preceding data may be variable length, in addition to being error prone when modifying the structure layout. Alignment types allow ResFool to automatically insert enough bytes to place the following field on a reasonable offset.
| AWRD, ALNG | Word/Long Alignment The word align field may insert a single byte. The long field may insert up to three bytes. Either field may be zero bytes. The smallest number of bytes will be added to make the next field in the template appear on a byte offset that is evenly divisible by two or four. As the data in the template changes, the alignment fields will expand or contract to keep the following field on a legal offset. The value of inserted bytes will be set to zero. |
| ALmm | Arbitrary Alignment The arbitrary align field may insert up to mm-1 bytes (or none). The smallest number of bytes will be added to make the next field in the template appear on a byte offset that is evenly divisible by mm. As the data in the template changes, the alignment field will expand or contract to keep the following field on a legal offset. The value of inserted bytes will be set to zero. For instance, to keep the following field on a 32-byte offset, set this field to AL32. |
A smattering of various types that defy categorization.
| CASE | Case The case field identifies a known value for a particular template field. It does not represent any actual data in the resource. The label of a case should have an identifying text string, an equal sign ("=") and a value consistent with the field it is being used for. When presented in the hex editor, a popup listing all the label names will be shown. Picking one will set the data of the associated field to whatever was specified after the equal sign. A template field may be followed by any number of CASE fields. The first CASE immediately following a template item will be used as the default value when creating the data for the resource (when an empty resource is opened). This makes a single CASE useful, even if the popup is not used. If you were creating a resource for a graphic object that had a name, height and width, where values of -1 for height and width meant using a default size, you might construct a template like this:
VIEW {
A CASE field whose label is a single hyphen ("-") will create a separator in the popup displayed while editing a resource. | ||||||||||||||||||||
| RSID | Resource ID This is a signed, two byte value that represents the ID of a resource. It is functionally equivalent to a DWRD type. Future versions of ResFool may provide additional functionality when a number is identified as a resource ID. | ||||||||||||||||||||
| DVDR | Divider Ignored. It is provided to support templates created for other resource editing applications. Future versions of ResFool may use this field to provide visual division of fields while editing a resource. | ||||||||||||||||||||
| RECT | Rectangle Identifies a rectangle consisting of signed, two byte values for a top, left, bottom and right. It is functionally equivalent to having four DWRD fields, though it is displayed as a collapsible entry when editing the resource. | ||||||||||||||||||||
| RGNC | Region Code This is a signed, two byte value that represents an Apple region code. It is functionally equivalent to a DWRD type. Future versions of ResFool may provide additional functionality when a number is identified as a region code. | ||||||||||||||||||||
| PNT<sp> | Point This is a pair of signed, two byte values that represents an x,y coordinate. It is functionally equivalent to two DWRD types, though it is displayed as a collapsible entry when editing the resource. Note this type is specified as 'PNT ' where the fourth character is a space. | ||||||||||||||||||||
| COLR | RGB Color This is a tuple of unsigned, two byte values that represents an RGB color. It is functionally equivalent to 3 UWRD types, though it is displayed as a collapsible entry when editing the resource. Future versions of ResFool may provide additional functionality when a tuple is identified as a color. | ||||||||||||||||||||
| HEXD, CODE | Hex/Code Dump Marks the remainder of the data in the resource as either unknown and uneditable hex data, or as machine code. In either case, the data cannot be edited from the template. Future versions of ResFool may provide additional functionality when editing data marked as CODE. |